
کار اصلی یک ربات وب، خزیدن یا اسکن وب سایت ها و صفحات انها برای جمع آوری اطلاعات است. رباتها به صورت خستگی ناپذیر جهت جمع آوری داده ها برای موتورهای جستجو و سایر برنامه ها کار می کنند. دلایل زیادی برای دور نگه داشتن صفحات از موتورهای جستجو برای بعضی از صاحبان وب سایت ها وجود دارد. فایل robots.txt به خزنده های وب و ربات ها اطلاع می دهد که اجازه دارند چه اطلاعاتی را جمع آوری کنند.
فایل Robots.txt چیست؟
robots.txt یک فایل متنی ساده در ریشه سایت شما است که از استاندارد حذف روبات ها پیروی می کند. به عنوان مثال، www.pouyasaza.org یک فایل robots.txt در www.pouyasazan.org/robots.txt خواهد داشت. این فایل شامل یک یا چند قانون است که دسترسی به خزنده ها را مجاز یا مسدود می کند و آنها را به یک مسیر فایل مشخص در وب سایت محدود می کند.
بهطور پیشفرض، تمام فایلها به طور کامل برای خزیدن مجاز هستند، مگر اینکه خلاف آن مشخص شده باشد. فایل robots.txt یکی از اولین جنبه هایی است که توسط خزنده ها تجزیه و تحلیل شده است.توجه به این نکته ضروری است که سایت شما فقط می تواند یک فایل robots.txt داشته باشد. این فایل در یک یا چند صفحه یا کل سایت پیاده سازی می شود تا موتورهای جستجو را از نمایش جزئیات وب سایت شما منصرف کند.
این متن پنج مرحله برای ایجاد یک فایل robots.txt و نحومورد نیاز برای دور نگه داشتن ربات ها را ارائه می دهیم.
چگونه یک فایل Robots.txt راه اندازی کنیم
یک فایل txt ایجاد کنید
شما باید به root دامنه خود دسترسی داشته باشید. ارائه دهنده میزبانی وب شما می تواند به شما کمک کند که آیا دسترسی مناسب را دارید یا خیر.
مهمترین بخش امکان ایجاد فایل است. از هر ویرایشگر متنی برای ایجاد یک فایل robots.txt استفاده کنید و می توانید آن را درمسیر های زیر قرار دهید
root دامنه شما:www.yourdomain.com/robots.txt.
زیر دامنه های شما: page.yourdomain.com/robots.txt.
پورت های غیر استاندارد:www.yourdomain.com:881/robots.txt.
توجه داشته باشید:
فایلهای Robots.txt در زیر شاخه دامنه شما (www.yourdomain.com/page/robots.txt) قرار نمیگیرند.
در نهایت، باید مطمئن شوید که فایل robots.txt شما یک فایل متنی با کد UTF-8 است. ممکن است Google و سایر موتورهای جستجو و خزندههای محبوب نویسههای خارج از محدوده UTF-8 را نادیده بگیرند و احتمالاً قوانین robots.txt شما را نامعتبر کند.
User-agent خود را txt تنظیم کنید
گام بعدی در نحوه ایجاد فایلهای robots.txt، تنظیم user-agent است. user-agent مربوط به خزندههای وب یا موتورهای جستجویی است که میخواهید اجازه دهید یا مسدود کنید ان ها را . چندین نهاد می توانند user-agent باشند. ما در زیر چند خزنده و همچنین ارتباط آنها را فهرست کرده ایم.
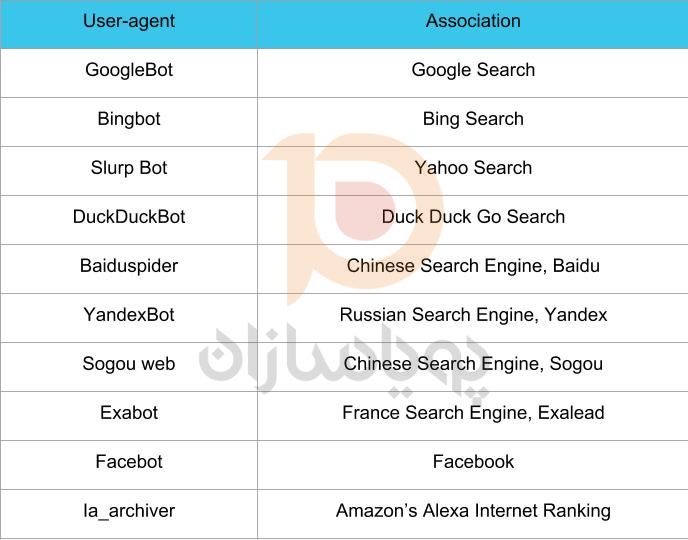
سه راه مختلف برای ایجاد یک user-agent در فایل robots.txt وجود دارد.
ایجاد یک User-agent
ساختار دستوری که برای تنظیم User-agent استفاده می کنیدبه صورت User-agent: NameOfBot است. در زیر، یک User-agent برای DuckDuckBot تعریف شده است.
# Example of how to set user-agent
User-agent: DuckDuckBot
ایجاد User-agent های بیشتر
اگر مجبور شدیم بیش از یک مورد اضافه کنیم، همان فرآیندی را که برای DuckDuckBot user-agent در خط بعدی انجام دادید، دنبال کنید و نام عامل کاربر اضافی را وارد کنید. در این مثال از Facebot استفاده کردیم.
#Example of how to set more than one user-agent
User-agent: DuckDuckBot
User-agent: Facebot
تنظیم همه خزنده ها به عنوان User-agent
برای مسدود کردن همه ربات ها یا خزنده ها، نام ربات را با یک ستاره (*) جایگزین کنید.
#Example of how to set all crawlers as
user-agentUser-agent: *
قوانین را برای فایل txt خود تنظیم کنید
یک فایل robots.txt به صورت گروهی خوانده می شود. یک گروه مشخص می کند که user-agent کیست و یک قانون یا دستورالعمل برای نشان دادن فایل ها یا دایرکتوری هایی دارد که user-agent می تواند یا نمی تواند به آن دسترسی داشته باشد.
در اینجا دستورالعمل های مورد استفاده آمده است:
Disallow: دستورالعملی که به صفحه یا دایرکتوری مربوط به دامنه اصلی شما اشاره می کند که نمی خواهید user-agent نامگذاری شده آن را بخزد. با یک اسلش رو به جلو (/) و سپس آدرس کامل صفحه شروع می شود. شما آن را با اسلش رو به جلو پایان می دهید تنها در صورتی که به یک دایرکتوری اشاره داشته باشد نه یک صفحه کامل. برای هر قانون می توانید از یک یا چند تنظیمات غیر مجاز استفاده کنید.
Allow: این دستورالعمل به صفحه یا دایرکتوری مربوط به دامنه اصلی شما اشاره می کند که می خواهید user-agent نامگذاری شده آن را بخزد. به عنوان مثال، شما می توانید از دستورالعمل اجازه برای لغو قانون عدم اجازه استفاده کنید. همچنین با یک اسلش رو به جلو (/) و سپس آدرس کامل صفحه شروع می شود. شما آن را با اسلش رو به جلو پایان می دهید تنها در صورتی که به یک دایرکتوری اشاره داشته باشد نه یک صفحه کامل. میتوانید از یک یا چند تنظیمات مجاز برای هر قانون استفاده کنید
Sitemap: دستورالعمل sitemap اختیاری است و مکان sitemap را برای وب سایت می دهد. تنها شرط این است که باید یک URL کاملا واجد شرایط باشد. بسته به آنچه لازم است می توانید از صفر یا بیشتر استفاده کنید.
خزنده های وب گروه ها را از بالا به پایین پردازش می کنند. همانطور که قبلا ذکر شد، آنها به هر صفحه یا دایرکتوری دسترسی دارند که صراحتاً روی Disallow تنظیم نشده باشد. بنابراین، Disallow: / را در زیر اطلاعات user-agent در هر گروه اضافه کنید تا مانع از خزیدن آن user-agent خاص در وب سایت شما شود.
# Example of how to block DuckDuckBot
User-agent: DuckDuckBot
Disallow: /
#Example of how to block more than one user-agent
User-agent: DuckDuckBot
User-agent: Facebot
Disallow: /
#Example of how to block all crawlers
User-agent: *
Disallow: /
برای مسدود کردن یک زیر دامنه خاص برای همه خزنده ها، یک اسلش و URL کامل زیر دامنه را در رول Disallow خود اضافه کنید.
# Example
User-agent: *
Disallow: /https://page.yourdomain.com/robots.txt
اگر می خواهید دایرکتوری را مسدود کنید، با اضافه کردن یک اسلش و نام دایرکتوری خود، همین روند را دنبال کنید، اما سپس با اسلش دیگر ان را پایان دهید.
# Example
User-agent: *
Disallow: /images/
در نهایت، اگر میخواهید همه موتورهای جستجو اطلاعات را در تمام صفحات سایت شما جمعآوری کنند، میتوانید یک قانون allow یا disallow ایجاد کنید، اما مطمئن شوید که هنگام استفاده از قانون allow ، یک اسلش اضافه کنید. نمونه هایی از هر دو قانون در زیر نشان داده شده است.
# Allow example to allow all crawlers
User-agent: *
Allow: /
# Disallow example to allow all crawlers
User-agent: *
Disallow:
فایل txt خود را آپلود کنید
وبسایتها بهطور خودکار با فایل robots.txt همراه نیستند، زیرا نیازی به آن نیست. هنگامی که تصمیم به ایجاد آن گرفتید، فایل را در فهرست اصلی وب سایت خود آپلود کنید. آپلود به ساختار فایل سایت و محیط میزبانی وب شما بستگی دارد. برای دریافت راهنمایی در مورد نحوه آپلود فایل robots.txt با ارائه دهنده هاست خود تماس بگیرید.
بررسی کنید که فایل txt شما به درستی کار می کند
راه های مختلفی برای تست و اطمینان از عملکرد صحیح فایل robots.txt وجود دارد. با هر یک از اینها، می توانید هر گونه خطا در ساختار نحوی یا منطق فایل خود دارید مشاهده کنید:
- آزمایشگر txt گوگل در کنسول جستجوی آنها (https://support.google.com/webmasters/answer/6062598)
- استفاده از txt Validator (https://technicalseo.com/tools/robots-txt/)
- ابزار تست txt Ryte. (https://en.ryte.com/free-tools/robots-txt/)
استفاده از Robots.txt در وردپرس
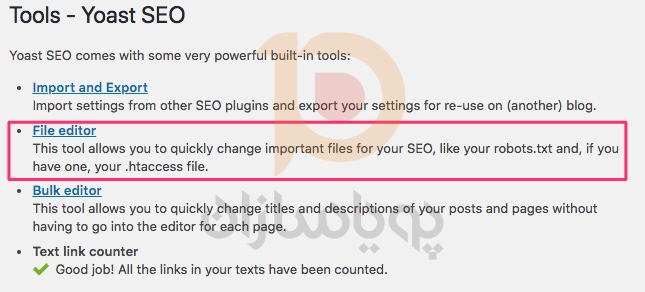
اگر از افزونه وردپرس Yoast SEO استفاده می کنید، بخشی را در پنجره مدیریت برای ایجاد یک فایل robots.txt خواهید دید.
وارد پیشخوان وبسایت وردپرس خود شوید و به Tools در بخش SEO بروید و سپس روی ویرایشگر فایل کلیک کنید.
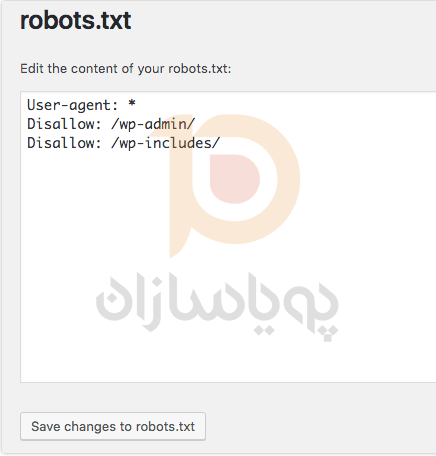
برای تعیین عوامل و قوانین کاربری خود، همان ترتیب قبلی را دنبال کنید. در زیر، ما خزندههای وب را از دایرکتوریهای wp-admin و wp-includes وردپرس مسدود کردهایم در حالی که همچنان به کاربران و رباتها اجازه میدهیم صفحات سایت دیگر را ببینند. پس از اتمام، روی ذخیره تغییرات در robots.txt کلیک کنید تا فایل robots.txt فعال شود.
نتیجه
ما نحوه ایجاد یک فایل robots.txt را بررسی کردیم. مراحل انجام آن ساده است و این فایل می تواند باعث جلوگیری از دردسر های می شود که به خاطر وجود ربات ها در سایت شما شود ایجاد می شود . برای جلوگیری از خزیدن غیرضروری موتورهای جستجو و ربات ها، یک فایل robots.txt ایجاد کنید.



